Muito se fala dessa área que vem crescendo no mercado de Tecnologia. Ok, mas vocês já conhece os caminhos que você poderia trilhar dentro da carreira de dados?

Esse é o objetivo deste artigo. Irei sanar suas dúvidas sobre os profissionais existentes e suas atribuições. Vamos lá?
- Por que esse profissional esta sendo tão procurado?
- Perfis de profissionais da carreira de dados?
- Engenheiro de dados
- Salário médio de um engenheiro de dados
- Analista de dados
- Ferramentas de Análise com foco em negócios
- Salário médio de um analista de dados
- Cientista de dados
- Tecnologias utilizadas pelos cientistas de dados
- Skills solicitadas por empresas
- Salário médio de um cientista de dados no Brasil
- Vídeo sobre Carreira em Data Science
Por que esse profissional esta sendo tão procurado?
Com o passar do tempo a computação evoluiu rapidamente, quase que de maneira exponencial. O resultado deste avanço esta refletido na criação de hardwares mais robustos, consequentemente, softwares mais potentes. O aprimoramento do hardware fomentou a evolução do software.
Quando geramos dados? Em uma simples navegação pela internet, consumindo páginas web, estamos produzindo uma infinidade de dados. Todo serviço disponibilizado na rede gera dados associados aos seus clientes. Esses dados precisam ser armazenados para análise posterior.
Ok… por que dizem que dados é novo ouro? Os dados influenciam diretamente em tomadas de decisões da empresa.
Podemos entender melhor o tamanho deste impacto com alguns exemplos, como: otimização de processos, aumento de lucro, maior taxa de engajamento, predição de valores, classificação e caracterização de comportamentos.

Perfis de profissionais da carreira de dados?
Dentro deste contexto quais são os profissinais que trabalham para lapidar esse diamente bruto (dados) e transforma-lo em informação útil para tomada de decisões?
Como cientista de dados percebo que ainda há uma certa “confusão” sobre as limitações de cada profissional. Ao pesquisar por vagas no linkedin, por exemplo, é comum encontrar atribuições de analista (ou engenheiro) ao cientista. Ainda assim, conseguimos encontrar um papel definido como analista com atuação de cientista.
Essa sobreposição de funções e mistura de nomenclaturas acaba acontecendo pelo pouco tempo de difusão da área no Brasil. Como a carreira de dados ainda está na sua infância, é comum perceber esse tipo de variação.
Dentro da carreira de dados podemos definir três papéis principais. Há outros no mercado, mas se você olhar de pertinho vai perceber que ele se encaixa em um destes três perfis que falaremos agora. Prosseguindo, quais são os profissionais de dados?
- Cientista de dados
- Analista de dados
- Engenheiro de dados
Engenheiro de dados
Muito bem, o que caracteriza um engenheiro de dados? Esse profissional está focado eno desenho, construção e manutenção de soluções para dados. Em outras palavras, esse profissional é responsável por tratar os dados e designar uma estrutura de armzenamento para esses dados de acordo com o contexto ou demanda.
Sendo assim, o engenheiro de dados vai determinar qual melhor sistema para prover persistencia destes dados. Após esta etapa poderão enfim ser analisados por outro profisisonal. Mais uma coisa de cada vez… Como isso acontece?
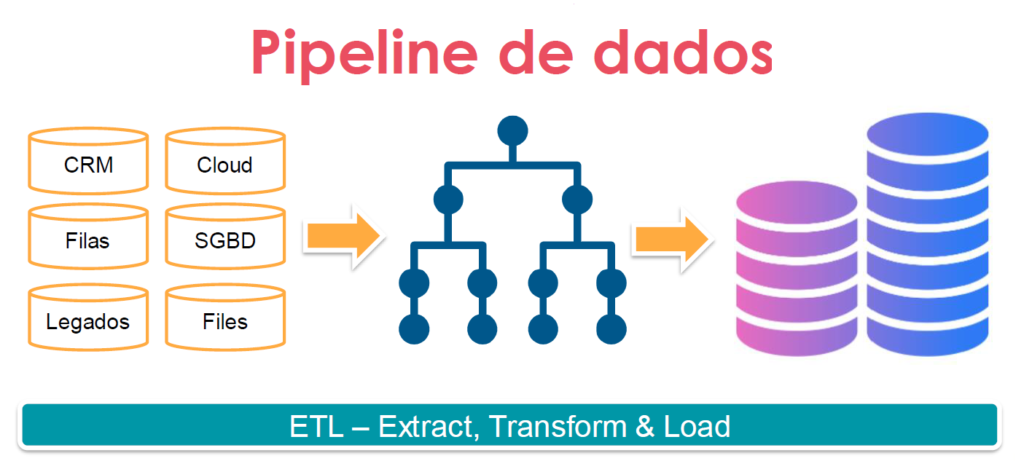
Processo de ETL
Um processo diretamente relacionado ao engenheiro de dados é conhecido como ETL – Extract Transform & Load. Resumidamente, esse processo é composto pelas etapas de coleta, limpeza, estruturação e manutenção de dados em um sistema.
Extract (Extrair)
Começando pelo extract, ou extração, já conseguimos ter uma ideia sobre esse passo do ETL. Aqui o engenheiro irá trabalhar com soluções de coleta de dados. Essas soluções podem incluir SGBDs Relacionais ou NoSQL.
Além disso, temos a disposição as linguagens de programação para trabalhar com APIs. Além disso, webscraping pode ser utilizado para coleta de dados. Antes de continuar, cabe ressaltar um questão…. cuidado para ultrapassar questões legais e realizar webscraping sem permissão.
Realizar coleta de informações de páginas utilizando esta técnica sem permissão pode ser considerado anti-ético. Apenas tenha certeza do que está fazendo.
Transform (Transformar)
Após a etapa de coleta de dados encaramos uma tarefa trabalhosa. A fase de transformação de dados está relacionada a limpeza e estruturação dos dados. Isso mesmo, limpeza. Esse termo é designado para descrever a etapa de refinamento dos dados.
Os dados não chegam prontos para uso. Além disso, na maioria das vezes os dados são coletados de fontes heterôgeneas para compor um mesmo contexto. Cada conjunto de dados tera uma estrutura distinta.
Cabe ao engenheiro retirar as redundâncias, informações desnecessárias, além de preencher lacunas quando possível. Dessa forma, ele será capaz de definir qual modelo estrutural utilizar para o processo de carregamento.
Nesta etapa você utilizará alguma linguagem de programação para transformar e automatizar, se necessário, esse processo. Importante ressaltar… os dados devem possui uma coesão a fim de terem significado. O valor das analises estão atreladas a qualidade dos dados.
Load (Carregar)
Agora os dados devem ser transferidos ao sistema correspondente de sua estrutura. Nesta caso, podemos citar: data lakes, SGBDs relacinais, NoSQL e outro sistema de armazenamento/gerenciamento de dados existe. Podemos ainda utilizar dessas soluções como serviço,em ambiente cloud.
Esta etapa consiste na adequação/configuração de sistemas. Além de uma possível integração entre sistemas. Consequentemente, o engenheiro manterá uma estrutura para os dados, moelados e persistidos, para análises posteriores.
O engenheiro em diversos momentos precisará manter a estrutura “redonda” para consumo dos analistas e cientistas. Quem sabe, até tratar questões de integração entre sistemas como MySQL e Power BI.
Paradigma Big Data
Com a evolução da tecnologia, aplicações em tempo real e grande volume de dados sendo gerados na Internet um novo paradigma surgiu: o Big Data. Imagine todo este processo agora atribuído ao contexto de grande volume de dados.
O paradigma do Big Data está fundamentado em 3 Vs: Velocidade, Variedade e Volume. Essas são as prinipais caracteristicas correspondentes ao Big Data.
O engenheiro de dados deve ser capaz de lidar com dados gerados em alta taxa de transmissão. Esses dados geralmente estão atreladados a alta demanda do sistema. Esse tipo de cenário possui um tratamento diferenciados dos dados “tradicionais”, ou seja, que seguem o modelo relacional.
Sistemas de gerenciamento de banco de dados NoSQL geralmente estão associados a este cenário. Dentre os NoSQL (lêia – Not Only SQL) posso citar as estruturas: wide-column, grafos, orientados a documentos, key-value, entre outros.
Os SGBDs NoSQL são utilizados em conjuntos com os relacionais para suprir as demandas de acesso das empresas. Um exemplo de mundo real é a tão conhecida Black Friday.
Para que SGBDs relacinoais possam suprir uma demanda avassaladora assim é preciso investimento em um crescimento vertical da infra. Isso acarreta em altos custos para suprir uma demanda pontual. Portante, ao invés de gastar pra deixar o servidor mais robusto podemos utilizar um SGBD NoSQL.
Os NoSQL herdam diversas características dos sistemas distríbuidos, como: escalabilidade, performance, falha independentes, heterogeneidade e transparência. Esses aspectos são muito interessantes em cenários como a Black Friday: pontuais e de alta demanda.
Fluxo de dados
Outra atribuição de um engenheiro de dados que acaba sendo solicitda pelas empresas são conhecimentos em arquiteturas de softwares avançadas, como: sistemas de mensageria e orientada a eventos. Esses sistemas possuem comunicação assíncrona.
Em diversos cenários uma comunicação assíncrona se torna mais interessante se comparada a um sistema tradicional. Vamos pensar um pouco… imagine que você comece a perceber um aumento na demanda de seus serviços.
Em um sistema síncrono as pontas devem estar online para que a operação seja em sucedida. Contudo, o servidor pode sofrer um overload, similar ao DoS, não sendo mais capaz de processar as informações.
Sistemas de mensageria e/ou eventos, com suas comunicações assíncronas, permitem uma melhor experiência do usuário. Neste caso, não será necessário investir verticalmente em infraestrutura da rede.
Um servidor que irá recuperar as mensagens pode faze-lo em momento posterior. Em outras palavras, o nó consumidor pode escolher quando processar uma informação. Isso fornece uma maior disponibilidade, performance e experiência do usuário.
Sobre estes sistemas, podemos citar os principais: RabbitMQ e Kafka
Quer saber mais sobre RabbitMQ?
Resumindo
O engenheiro é responsável pelas soluções/sistemas com gerenciamento e persistência de dados, provendo uma estrutura pronta para análise posterior.
Tópicos de estudo para carreira de engenheiro de dados
- SGBDs relacional e NoSQL
- Python, Java
- Orquestração de containers e Clusterização
- Sistemas orientados a eventos
- Sistemas de mensageria
- Processo de ETL
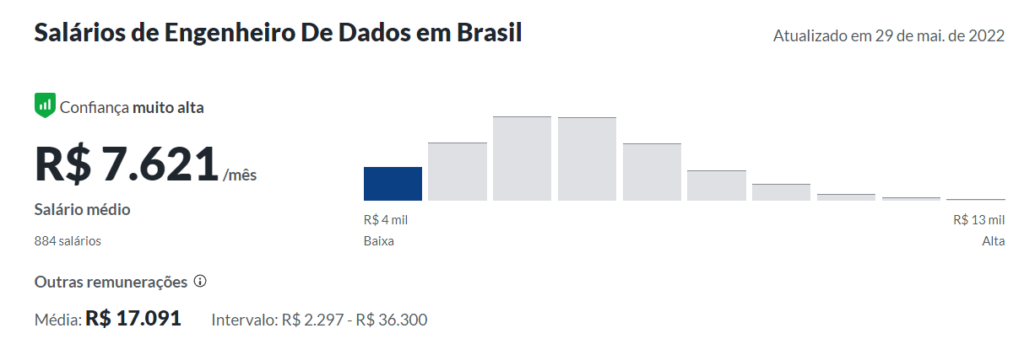
Salário médio de um engenheiro de dados
O salário médio de um engenheiro de dados de acordo com www.glassdor.com está aproximadamente em 7mil reais. Existem variações de acordo com o nível de cada profissional. Engenheiros sênior podem ter remuneração na faixa de 10mil reais.
Analista de dados
O foco do analista de dados está concentrado na análise dos dados voltados para negócios. Seu principal objetivo está em demostrar diretivas e resultados de métricas da empresa de forma visual.
Sendo assim, este profissional precisa conhecer o contexto em que a empresa está inserida. Dessa forma, ele será capaz de formular as perguntas mais adequadas para seu cenário.
Geralmente, responde perguntas ligadas as diretivas e regras de negócio. O analista de dados deve ser capaz “contar” a história dos dados através de dashboards, gráficos, relatórios e outros artifícios visuais.
Exemplos práticos estão associados a relatório de vendas, marketing, finanças, governos, indústria e outros ramos voltados para o mercado.
Um analista precisa entender o contexto dos dados, analisa-los a fim de inferir informações e insights, assim como apresenta-los aos stakeholders. Uma vez que tenha encontrado as respostas a suas perguntas, determinado padrões dentro dos dados é preciso visualiza-los.
Na maoria dos casos o analista irá recuperar os dados a partir de SGBDs. A maioria dos cenários de negócios utilizam sistemas tradicionais de banco de dados relacionais. Sendo assim, o analista deve ter conhecimentos em SQL.
A partir desses dados, o analista irá utilizar a abordagem de BI – Business Intelligence – para analisar os dados. Com a análise em mãos, o analista será capaz de responder as perguntas e criar relatórios e dashboards.
Pontos cruciais para um analista de dados
- Pensamento analítico para transformar dados em informação
- Entender de vendas e negócios
- Saber a diferença entre valor e preço
- Transformar dados em tomadas de decisão que influenciem na saúde da empresa
- Trabalho em equipe (time de dados: engenheiro, analista e cientista)
Ferramentas de Análise com foco em negócios
O foco no analista está na análise de negócios. Sendo assim, as ferramentas utilizas por este profissional englobam:
- SAP e SPSS
- Excel, ou Google Sheets
- Tableu ou Power BI, Qlik
- SGBDs relacionais – SQL
Salário médio de um analista de dados
Média salarial com base no site glassdoor.

Cientista de dados
O que de fato é um cientista de dados?
A ciência de dados é um ramo interdisciplinar, onde o profissional irá converter dados em informação útil e insights. As áreas contempladas pela ciência de dados são: computação, matemática e modelagem.
Um cientista de dados utiliza-se de técnicas de computação com modelos e métricas, baseadas na matemática estatística, a fim de obter insights e gerar inferências sobre um contexto.
O pensamento exploratório e analítico acompanham o cientista de dados em seu cotidiano. Sendo assim, o cientista busca nos dados informações que expliquem o contexto em que estes dados estão inseridos. Caracterização, classificação, predição e interpretação do contexto fazem parte de seu repertório.
Apesar do trabalho do cientista ser bem delimitado, muitas vezes este profissional executa tarefas atribuídas à outras profissões de dados. Sendo assim, é preciso que o cientista tenha conhecimento do processo de ETL. Dessa forma, ele terá uma visão macro da situação.
Muitas vezes, um cientista precisará executar coleta, limpeza, transformação dos dados para haja uma análise posterior. Todo este processo pode ser executado utilizando a linguagem de programação Python (ou outra de sua preferência). Além disso, é possível que o cientista tenha de representar graficamente seus insights.
Ok… qual a diferença entre o analista e cientista?
O analista está preocupado com o viés de negócios. Portanto, ele precisa ter o Known How de negócios. Outra característica deste profissional está na sua perspectiva de tempo. O analista está atento ao passado. A entender como os indicadores de uma empresa evoluíram no decorrer de um período.
O cientista está preocupado em entender o snapshot fornecido pelos dados. Por isso, ele foca em tarefas como caracterização, classificação e predição (previsão) de acontecimentos. Seu olhar está mais par o futuro se comparado ao analista.
Entendendo um pouco mais …
O paradigma do Bid Data também está presente aqui. Muitas vezes o cientista ira analisar dados que fogem ao padrão tradicional do modelo relacional. Sendo assim, precisa estar munido de técnicas de análise de grande volume de dados.
Além destas skills, as empresas vem solicitando conhecimento em processamento de linguagem natural – NLP. Com a popularização de agentes de IA, os dados passaram a ter outra conotação. Isto precisa ser tratado pelo cientista.
Falamos em técnicas para analisar os dados com olhar de cientista. Então, quais são essas técnicas? Podemos separar as técnicas em três grandes áreas dentro da Ciência de Dados (Data Science). São elas: Machine learning, Network Data Science, e Estatística. Falaremos sobre elas brevemente.
Abordagem Estatística
A estatística e álgebra linear fazem parte da vida de qualquer profissional de análise de dados. Contudo, os dados podem ser analisados com viés puramente estatístico. Isso acontece muito no âmbito acadêmico. Estatísticos e matemáticos utilizam de recursos matemáticos para modelar e explicar fenômenos através de equações matemáticas.
Além disso, podemos ver esse cenário dentro da computação teórica. Temas de computação como criptografia são puramente baseados na matemática. Contudo, no mercado você perceberá que a matemática é aplicada aos modelos de machine learning e métricas de análise com redes complexas.
Network Data Science
Network Data Science, ou redes complexas, utiliza da teoria de grafos para modelar, caracterizar e analisar os dados. Neste caso, os dados são modelados para estrutura de nós (atores) e conexões (relacionamentos).
Após a modelagem podemos aplicar métricas específicas desta área, como: centralidade de grau, pagerank, betwenness, entre outros. O algoritmo de Pagerank é utilizado pelo Google para indexar as páginas no buscador.
Diferentemente da estrutura tradicional, modelo relacional, podemos definir relacionamento para os dados. Esta estrutura em grafos representa muito bem diversos cenários do mundo real. Podemos encontrar a estrutura de redes complexas em cenários como:
- Redes sociais (usuários e amizades)
- Redes de autores e publicações
- Redes de transações bancárias
- Mapeamento de DNA (conexão entre os cromossomos)
- Redes de transporte público
- Linhas aéreas (cidades e rotas de voo)
Podemos alinhar esta abordagem, redes complexas, com diversas técnicas matemáticas, como: correlação, auto-valor e auto-vetor, probabilidades. Sendo assim, podemos utilizar as bibliotecas do Python para criar uma análise robusta.
Algumas destas bibliotecas são: Numpy, Pandas, e NetworkX (Redes complexas).
Machine Learning
As técnicas de aprendizagem de máquina, ou mesmo IA, podem contribuir para suas análise de dados. Muitas vezes o trabalho de análise de dados realizado pelo data scientist vem antes da aplicação dos modelos de ML. Afinal de contas… podemos ter um modelo incrível, mas com dados ruins não teremos bons resultados.
Diferentemente de data science, machine learning é uma campo da computação que trabalha com sistemas informais que possuem a capacidade de aprender. Claramente, estes sistemas são treinados para que possam opinar sobre dados desconhecidos. Sendo assim, o contexto é fornecido pelos dados de treinamento.
Neste contexto, existem algumas abordagens: IA, inteligência artificial, que é uma ramo por si só, mas fornece base para ML; Deep learning – aprendizado profundo – com modelos específicos desta área.
O objetivo com Machine Learning está no reconhecimento e detecção de padrões nos dados processados. Para qualidade dos resultados precisamos dar uma atenção considerável aos dados de treinamento.
Em resumo… em qualquer análise a qualidade dos dados influencia no resultado.
Visualização de dados
Um cientista de dados deve ser capaz de expressar seus resultados de maneira clara, objetiva e explicativa. Portanto, o cientista de dados deve possuir a Soft skill de contação de histórias, ou Storytelling.
Para expor os resultados visualmente podemos utilizar bibliotecas para plotagem de gráficos, como Matplotlib (site oficial) do Python.
Seguindo ainda neste assunto, podemos utilizar ferramentas de criação de dashboards, como: Power BI, Tableu, e Qlike. Utilizando essas ferramentas podemos dar vida aos dados por dashboards interativos.
Existem diversos recursos associados a estas ferramentas. O Power BI, por exemplo, pode ser integrado com power point para criar a apresentação do resultados.
Tecnologias utilizadas pelos cientistas de dados
Python é utilizado massiamente pelos cientistas de dados. Sendo assim, todo o processo pode ser construído com ele. Em outras palavras, o processo de coleta, limpeza, modelagem, análise e representação visual.
Contudo, podemos citar outras ferramentas importantes.
- Análise de dados com Python
- Banco de dados relacional – SQL
- Banco de dados NoSQL
- Apache Spark
- Jupyter Notebook ou Google Colab
Skills solicitadas por empresas
Neste tópico quero falar com vocês de assuntos que extrapolam as skills base de um cientista de dados. Como conhecimento nunca é demais vale a pena estar atento aos seguintes temas:
- Git (versionamento)
- Docker & Kubernetes
- MLOps – deploy e manutenção de ML models
- IA – Inteligencia Artificial
- BI Tools
Das ferramentas de BI podemos citar: Power BI, Google Data Studio, Tableu, Qlike, Locker, entre outros.
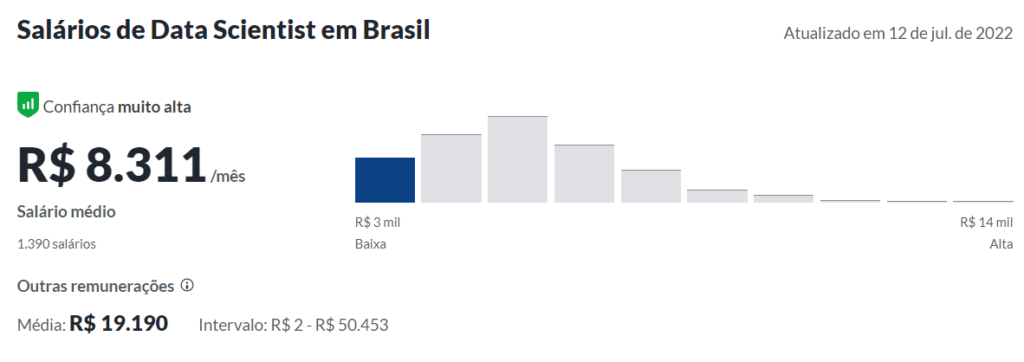
Salário médio de um cientista de dados no Brasil
Média salarial com base no site glassdoor.