Quais são as principais bibliotecas python para data science?
A ciência de dados nos permite explorar, analisar e compreender o vasta gama de fenômenos, comportamentos e contextos que nos cerca.

Com diversas opções disponíveis é possível se perder na tentativa de definir a ferramenta, linguagem ou biblioteca ideal para cada caso.
Para outros assuntos de DS acesse o canal SR ou artigos tais como carreiras em dados “Por onde iniciar a carreira em dados?”
Python de fato é a primeira opção para o mundo de Dados. Mas quais libs utilizar?
Neste caso iremos verificar algumas das libs que compõe um ecossistema repleto de bibliotecas poderosas e versáteis.
Quais são as principais bibliotecas python para data science que iremos abordar?
Focaremos nas libs projetadas especialmente para manipulação e visualização de dados.
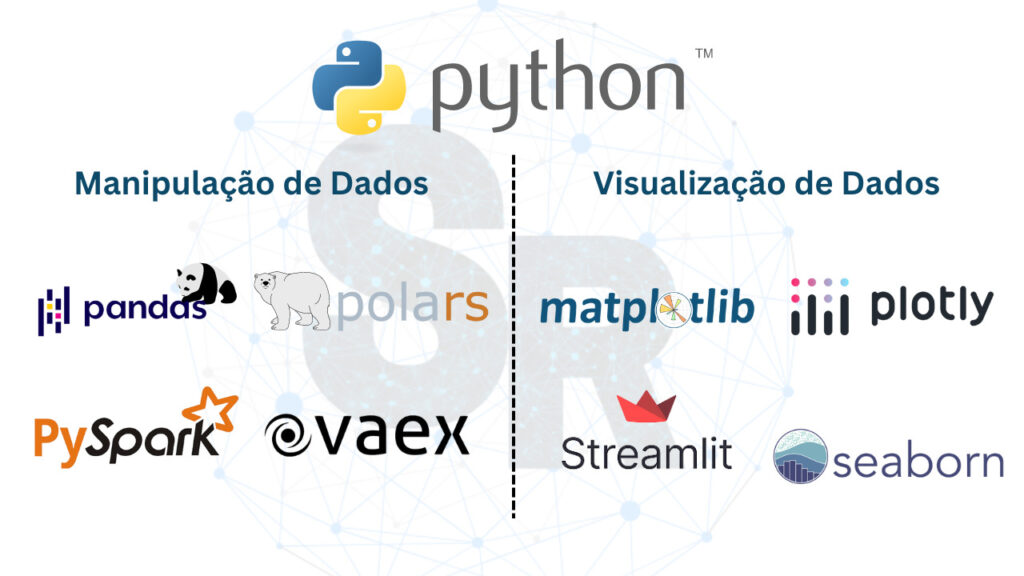
Através dessas ferramentas, poderemos extrair insights valiosos, criar visualizações atraentes e contar histórias que envolvam nosso cliente a partir dos nossos dados.
Para a habilidade de uma história bem contada, da-se o nome de Storytelling.
Vamos então explorar as principais bibliotecas e APIs em Python para Data Science!
Explorando Dados com Python
Seja cientista ou analista de dados, nosso trabalho gira em torno da análise e compreensão dos dados relaciondos a um negócio, ou outra área do conhecimento.
E para tornar esse processo mais eficiente e agradável, contamos com algumas das melhores bibliotecas de manipulação e visualização de dados em Python.
Neste artigo, vamos explorar algumas das mais poderosas: pandas, polars, vaex, pyspark, matplotlib, plotly e seaborn.
Vamos começar então pela manipulação de dados. Quais são as principais bibliotecas python para data science para transformação de dados?
Bibliotecas Python Data Science: Manipulação e Tratamento de Dados
Biblioteca pandas: Dominando a Manipulação de Dados
A biblioteca pandas é uma das mais queridas e essenciais para qualquer data scientist.

Ela nos oferece estruturas de dados versáteis como DataFrames e Series, que facilitam a manipulação e análise de dados tabulares.
Com pandas, podemos realizar uma diversas tarefas atreladas ao processo Transformação de dados (emt ETL), tais como:
- Limpeza de dados,
- Tratamento de valores ausentes,
- Agregação de informações,
- Filtragem,
- Ordenação
- Conversão em outras estruturas e muito mais.
O alinhamento dos dados baseados em rótulos de índice é uma das grandes vantagens da biblioteca.
Assim, conseguimos evitar muitas dores de cabeça usuais na manipulação de dados.
Abaixo você terá um pequeno exemplo em python com pandas.
import pandas as pd
# Criar um DataFrame simples
data = {'Nome': ['João', 'Maria', 'Pedro', 'Ana'],
'Idade': [25, 30, 22, 28],
'Cidade': ['São Paulo', 'Rio de Janeiro', 'Belo Horizonte', 'Brasília']}
df = pd.DataFrame(data)
# Exibir o DataFrame
print(df)
# Calcular a média das idades
media_idades = df['Idade'].mean()
print("Média das idades:", media_idades)
Além do tratamento dos dados, podemos utilizar o pandas para realizar cálculos com estatísticas descritivas, como ex: média e desvio padrão.
Além disso é possível criar ou criar gráficos de barras e histogramas. Isso é muito útil durante um processo exploratório dos dados. Ou ainda em uma análise preliminar.
Biblioteca Polars: A Alternativa Eficiente com Performance
Quando lidamos com grandes conjuntos de dados, o pandas pode ter limitações de desempenho, especialmente com relação ao consumo de memória.
Para esses casos a biblioteca polars entra em cena.
Polars é uma biblioteca moderna, escrita em Rust com alto poder para manipulação de dados tabulares em cenário com pouca memória disponível.

Da mesma forma que o pandas ela trabalha com dataframes. Contudo, tem um desempenho superior em cenários com carga mais alta de processamento de dados.
Essa vantagem ocorre pela lib aproveitar ao máximo a paralelização e o processamento eficiente de dados.
Polars é uma escolha ideal para operações em CPU, acarretando em um aumento significativo na velocidade de processamento de grandes volumes de dados.
Abaixo você terá um pequeno exemplo em python com polars.
import polars as pl
# Criar um DataFrame simples
data = {'Nome': ['João', 'Maria', 'Pedro', 'Ana'],
'Idade': [25, 30, 22, 28],
'Cidade': ['São Paulo', 'Rio de Janeiro', 'Belo Horizonte', 'Brasília']}
df = pl.DataFrame(data)
# Exibir o DataFrame
print(df)
# Calcular a média das idades
media_idades = df['Idade'].mean()
print("Média das idades:", media_idades)
Nossa próxima lib também trabalha com uma alta carga de dados.
Biblioteca Vaex: Velocidade e Eficiência para Dados Gigantescos
Se a eficiência é a chave para manipular conjuntos de dados gigantescos, o vaex é uma lib interessante para seu caso.
Essa biblioteca proporciona um desempenho surpreendente, permitindo que você trabalhe com dados de dimensões colossais com facilidade.
Devido a utilização de computação assíncrona e lazy evaluation na realização das operações com os dados, opera de maneira rápida e eficiente.
Além disso, opera sem sobrecarregar a memória do sistema. Isso torna o vaex uma opção de alta performance para manipular Big Data em Python.
O único ponto de atenção está relacionado a menor adesão em ambiente de produção. As bibliotecas mais famosas como pyspark ganham destaque neste caso.
Abaixo temos um exemplo de python usando vaex.
import vaex
# Criar um DataFrame simples
data = {'Nome': ['João', 'Maria', 'Pedro', 'Ana'],
'Idade': [25, 30, 22, 28],
'Cidade': ['São Paulo', 'Rio de Janeiro', 'Belo Horizonte', 'Brasília']}
df = vaex.from_dict(data)
# Exibir o DataFrame
print(df)
# Calcular a média das idades
media_idades = df['Idade'].mean().item()
print("Média das idades:", media_idades)
Biblioteca Pyspark: Escalabilidade e Processamento Distribuído
Quando o tamanho dos seus dados ultrapassa os limites de uma única máquina, o pyspark é a solução para lidar com o processamento distribuído em um cluster.
Essa biblioteca é baseada na plataforma Apache Spark e fornece uma interface amigável para realizar tarefas de manipulação e processamento de Big Data.
Quando falamos de processamento paralelo de dados, pyspark é a primeira opção da lista. Acontece da mesma forma com o sistema Spark.
O pyspark oferece recursos poderosos, como a execução paralela de tarefas, suporte a SQL, machine learning, RDDs (Resilient Distributed Datasets), processamento in-memory e processamento de streaming.
Essa combinação de escalabilidade e facilidade de uso torna o pyspark uma opção valiosa para análise de dados em larga escala.
Abaixo você terá um pequeno exemplo utilizando a lib pyspark em python.
from pyspark.sql import SparkSession
# Iniciar uma sessão Spark
spark = SparkSession.builder.appName("Exemplo").getOrCreate()
# Criar um DataFrame simples
data = [('João', 25, 'São Paulo'),
('Maria', 30, 'Rio de Janeiro'),
('Pedro', 22, 'Belo Horizonte'),
('Ana', 28, 'Brasília')]
columns = ['Nome', 'Idade', 'Cidade']
df = spark.createDataFrame(data, columns)
# Exibir o DataFrame
df.show()
# Calcular a média das idades
media_idades = df.selectExpr("avg(Idade)").collect()[0][0]
print("Média das idades:", media_idades)
Quais são as principais bibliotecas python para data science para visualização de dados?
Biblioteca Python Data Science: Visualização de Dados
A visualização de dados é um ponto importantissímo do processo de análise de dados. Nós precisamos passar as informações para o cliente, caso contrário, será o mesmo que não executar o trabalho.
Biblioteca Matplotlib: Personalização e Versatilidade em Gráficos
A biblioteca matplotlib é uma das mais populares para visualização de dados em Python.
Ela oferece um alto grau de personalização e versatilidade na definição dos gráficos. Conseguimos criar relatórios com aparência profissional e que atendam às nossas necessidades do nosso clinte.
Acredito que foi uma das primeiras libs de visualização que utilizei. Ideal para criação de relatórios com gráficos e dados estáticos.
Caso você precise de interação, e “vida” em seus dados aconselho explorar libs, tais como: Streamlit e Plotly.
Abaixo você terá um pequeno exemplo de utilização do matplotlib com python
import matplotlib.pyplot as plt
# Dados para o gráfico de barras
cidades = ['São Paulo', 'Rio de Janeiro', 'Belo Horizonte', 'Brasília']
populacao = [12252023, 6747815, 2512072, 3055149]
# Criar o gráfico de barras
plt.bar(cidades, populacao)
# Adicionar título e rótulos
plt.title('População por Cidade')
plt.xlabel('Cidades')
plt.ylabel('População')
# Exibir o gráfico
plt.show()
Biblioteca plotly: Visualizações Interativas e Dinâmicas
Enquanto o matplolib é ideal para relatório estáticos, o plotly é dinâmico e low code.

Sendo uma poderosa biblioteca Python de código aberto, o plotly oferece recursos avançados para criação de visualizações interativas e dinâmicas.
Podemos criar visuais interesantes e interativos em 2D e 3D, permitindo a exploração dos dados a partir de diferentes perspectivas. Além disso, podemos ainda criar Apps!
Assim, você da poder ao usuário na jornada pelos dados. Ele escolhe o nível de detalhemento necessário.
Os relatórios se tornam personalizáveis e objetivos.
Sua integração com outras bibliotecas Python, como o pandas e o matplotlib, facilita a manipulação e personalização dos gráficos.
Além disso, o Plotly é altamente customizável, tornando-se uma ferramenta valiosa para analistas de dados que desejam comunicar seus resultados de forma atraente e informativa.
Abaixo você poerá ver um exemplo de utilização do plotly.
import plotly.express as px
# Dados para o gráfico de dispersão
x = [1, 2, 3, 4]
y = [10, 15, 13, 17]
labels = ['Ponto 1', 'Ponto 2', 'Ponto 3', 'Ponto 4']
# Criar o gráfico de dispersão
fig = px.scatter(x=x, y=y, text=labels)
# Adicionar título e rótulos
fig.update_layout(title='Gráfico de Dispersão',
xaxis_title='Eixo X',
yaxis_title='Eixo Y')
# Exibir o gráfico
fig.show()
Biblioteca Seaborn: Criando Visualizações Impactantes
O Seaborn é uma biblioteca de visualização de dados em Python construída sobre o Matplotlib com foco estatístico.
Ele fornece uma interface de alto nível para criar gráficos estatísticos atraentes e informativos.
O Seaborn foi projetado para funcionar perfeitamente com DataFrames e arrays do pandas, facilitando a visualização de conjuntos de dados complexos.
A biblioteca oferece uma ampla variedade de tipos de gráficos, incluindo gráficos de dispersão, gráficos de barras, box plots, mapas de calor e muito mais. Essas são opções mais elaboradas que refletem análises mais complexas dos dados.
Uma das principais vantagens do Seaborn é a capacidade de criar gráficos visualmente atraentes com apenas algumas linhas de código, abaixo você terá um exemplo em python.
Além disso, o Seaborn oferece ferramentas para personalizar e ajustar facilmente os gráficos de acordo com requisitos e suas variações.
import seaborn as sns
# Dados para o gráfico de dispersão
x = [1, 2, 3, 4]
y = [10, 15, 13, 17]
# Criar o gráfico de dispersão usando seaborn
sns.scatterplot(x=x, y=y)
# Adicionar título e rótulos
plt.title('Gráfico de Dispersão')
plt.xlabel('Eixo X')
plt.ylabel('Eixo Y')
# Exibir o gráfico
plt.show()
Como escolher a lib correta para seu projeto?
Com tantas opções disponíveis, é importante saber escolher a biblioteca certa para o seu projeto.
Considere fatores como o tamanho dos dados que você está trabalhando, a eficiência e desempenho desejados, as funcionalidades específicas que você precisa e a facilidade de uso da biblioteca.
Experimente diferentes bibliotecas, veja como elas se adequam às suas necessidades e escolha aquela que melhor se encaixa em seu projeto

Juliana Mascarenhas
Data Scientist and Master in Computer Modeling by LNCC.
Computer Engineer
Leia outros posts do SR!
Quer saber mais sobre Carreira em Dados ?
Acesse os vídeo em nosso canal no Youtube Simplificando Redes