What are a relational DBMS’s main characteristics or, better, features? When to choose a database? Is there a scenario where it is not used? This article deals precisely with this subject.
If you want to better understand what databases are really about, access the first article on the topic: Understand what databases are
You might be wondering… “But traditional ways of storing and processing data (files, for example) solve the problem. Why use a DBMS?
Let’s understand the differences in the approach of old mechanisms (eg files) of data processing with the DBMS approach.
Recalling the Traditional Approach
Recalling what was said in the article Understand what databases are , in a traditional approach, the developer defines the data management requirements of both the program and the type of storage to be used.
Thus, the files are part of the implementation of the program. Everything seems right, but some points are problematic. An example of this is access concurrency control and redundancy.
In this way, there will be data repetition, ie redundant data storage unnecessarily. We can then see the problem of wasted storage space and rework.
Characteristics of a DBMS
A DBMS is based on the utilization approach of a single repository that holds the data. Clearly, we are not considering a distributed environment. That’s a subject for another post….
These data, in turn, are accessed by different applications, or retrieved through queries and transactions. The DBMS is responsible for storing, managing, controlling and maintaining the consistent state of the data.
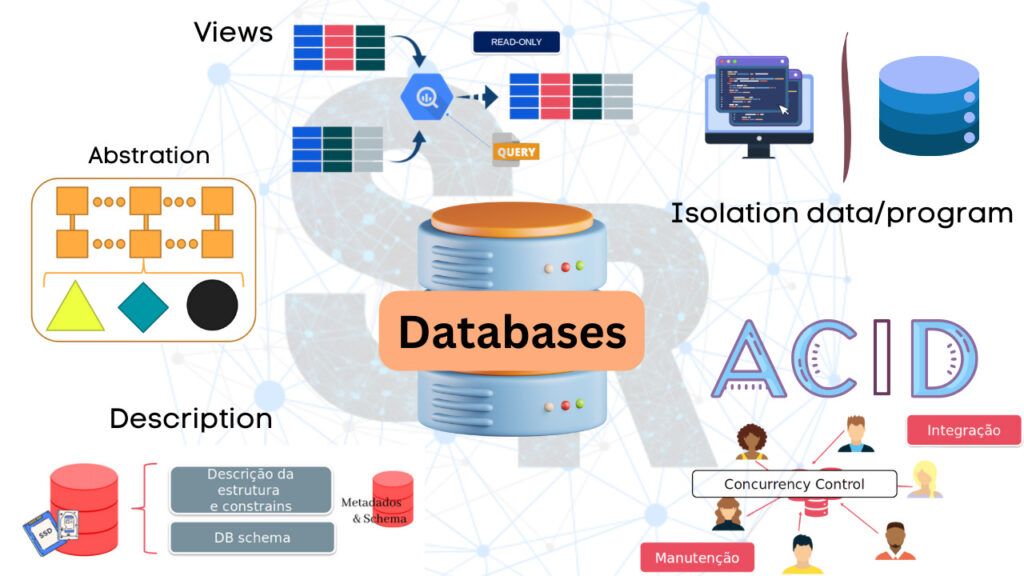
We can describe a DBMS by its main characteristics, then describing the DB approach. They are:
- Self-description
- Isolation between data and program
- Data abstraction
- Support multiple views of persisted data
- Data sharing
- Multi-user transaction processing
Self-descriptive nature of the DBMS
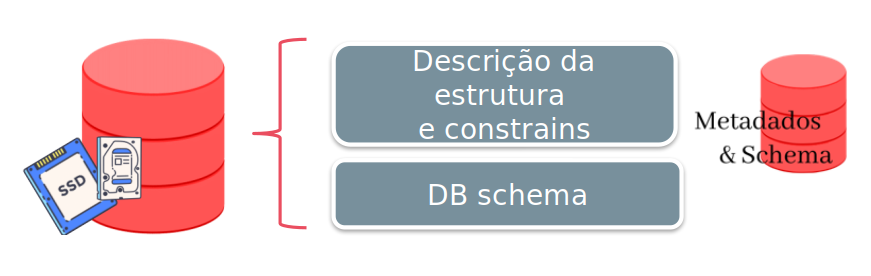
This feature comes from the fact that the DBMS contains in addition to the database the metadata information and description of the database schema.
In other words, the DBMS has a complete description of the structure and constraints of the database.
This structure is called a catalog. It contains the structures of the files, the type and format of, that is, the metadata. This DBMS module is also known as the metadata catalog.
P.S. NoSQL based systems do not use metadata, as each data structure is self-descriptive containing the name and value of the items.
The catalog is used both by the DBMS and by users who need information about the database.
When you run DESC <table> in MySQL you retrieve the metadata of the table in question.
The DBMS should work normally regardless of the type of application that uses the data: university data, databases from banks, or companies, as long as the definition of the database is defined in the catalog.
Can you see that in the “traditional” (or archaic) approach, each application needed to be concerned with the context of the data? Well, one more point for the DBMS.
As such, the application would typically access and manage the data structure, which in this case is part of the application program.
In the scenario where the DBMS is dedicated to data, the program accesses the data in a “transparent” way, sending only little information about the data to be recovered.
Like ex: SELECT CONCAT(name,’ ’, lastname), email, phone FROM CUSTOMERS WHERE YEAR(data_login) == YEAR(current_date())
The DBMS, in turn, is capable of accessing different types of databases by extracting and using information from the metadata catalog.
Program and Data Isolation – DBMS
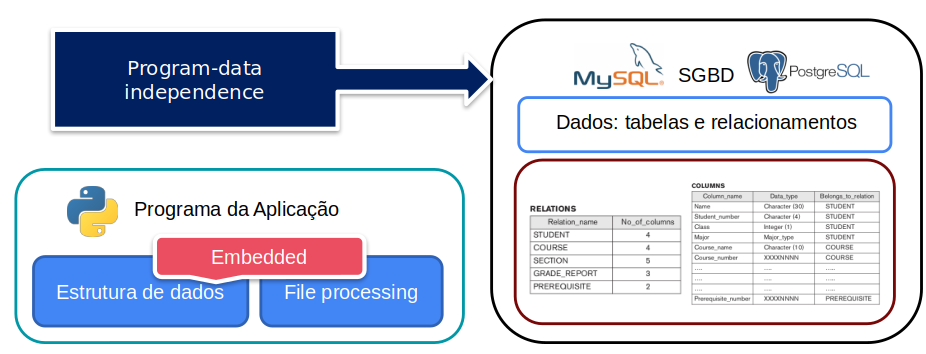
In the “archaic” approach, the data structure is embedded, or “embedded”, in the application. This creates a number of code creation and maintenance complications.
Any changes to the structure one of the files will directly impact the application.
However, in the DBMS there is a clear separation between the DB structure and the data itself. This process is called program/data independence.
Isolation/abstraction example
Let’s understand better ….
Assume a program written to access a database of students. This program contains the data structure.
Now, imagine that there is a need to modify this structure and add the date of birth field. The entire program will be restructured to accommodate this change. Otherwise, it will fail.
On the other hand, a DBMS has the isolation feature that should reflect this change only in the DB catalog.
This way, when the DBMS looks for this attribute when accessing the catalog, the new structure will be accessed.
NOTE: Despite this isolation, sudden changes in the database schema are not trivial and come with downtimes and other questions.
When we talk about modeling, we need to be aware of the best possible way to represent this data.
Abstraction
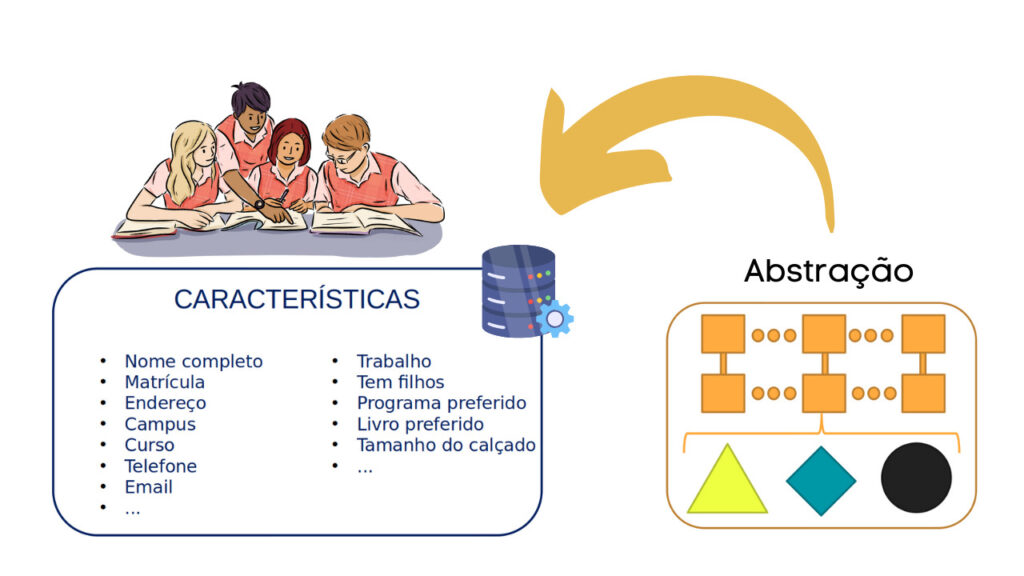
Continuing … The characteristic that allows this independence between data and program is Abstraction. The program abstracted the structure, delegating this task to the DBMS.
“Well, Juliana? How does the application request the data?” With prior knowledge of the tables and attributes that make up the DB in order to create SQL queries.
We then have a conceptual representation of the data without the need to introduce implementation details such as storage and operations. We have what is called a data model.
Informally, the data model is the abstraction of the data itself used in the representation of the mini-world. This model is composed of logical concepts such as: objects, properties and interrelationships.
The operations contained in the application will use the data model as a basis to perform your queries and retrieve, add, remove or update data in the DBMS.
Table Views
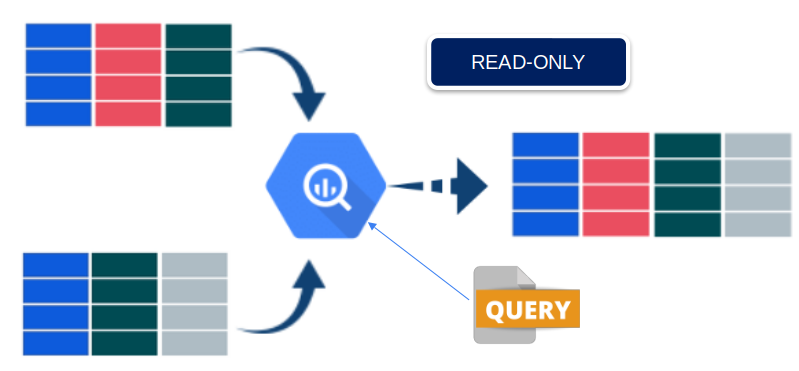
One of the great features of DBMS, are the “views” play a fundamental role in improving the interaction between user and stored data.
Views, also known as views, provide a virtual representation of the data contained in associated tables. This allows users to perform complex queries and analysis without the need to directly access the original tables.
This happens transparently as the DBA, or database analyst, creates views based on the most frequently asked questions.
One of the main advantages of views is the reduction of bandwidth consumption and system resources. In queries involving multiple tables and complex operations, views act as middle layers.
They store the results of frequently used queries and queries, minimizing the need to repeat calculations and reducing system overhead.
In addition, there are other advantages of using it. These I will leave for a post dedicated to the subject.
However, not everything is rosy. There are times when views can get in the way. An example is accessing data in real time, since the biases are originated by pre-processing the data.
SHARING AND MULTIUSER
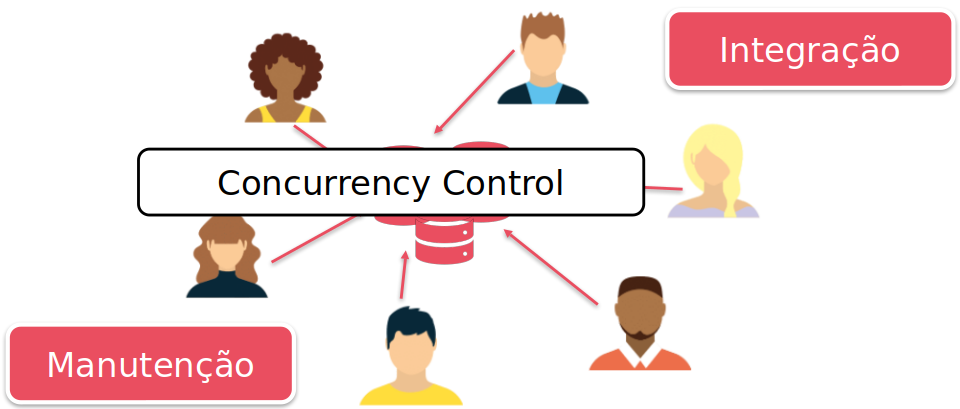
It is common in database environments for multiple concurrent transactions to be executed. This is one of the reasons for its use.
Thus, issues such as consistency, isolation, and atomicity need to be carefully managed. For this, several algorithms and techniques are employed.
When we talk about relational database it is right to associate the acronym ACID to it. Transactional systems need to support the ACID model. But what does ACID mean?
- A – Atomicity
- C – Control
- I – Isolation
- D – Durability
To better understand this scenario let’s understand each part of the acronym. Atomicity is associated with the characteristic of the data persisted in the database.
The data must be atomic, in other words immutable. The data to be entered into the system must obey the rules related to the attribute (field).
This data is entered through transactions. These transactions are either 8 or 80, i.e. it either happens without errors or goes back to the previous consistent state. Commit or abort
Control relates to the DBMS’s control over transactions. The control is related to the consistent state of the database. Control = data consistency
Isolation keeps the operation independent of transactions. Therefore, a running transaction cannot be interfered with by another transaction submitted to the DBMS.
Finally… you may have noticed that traits are interdependent. This means that each aspect of the ACID acronym positively influences the other.
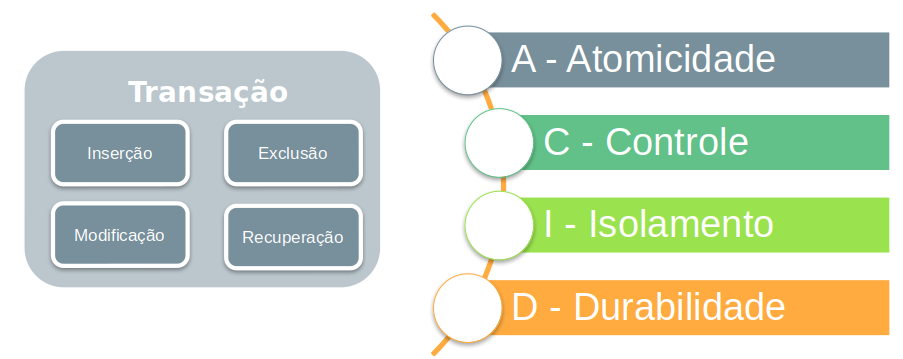
Our last element, D – Durability, is related to ensuring successful modification of data during the transaction, even in case of system failure.
What are blocks?
In cases of server crash, for example, the DBMS can recover the state before the failure through the system logs.
Among the main algorithms adopted for concurrency control by a DBMS, we have:
Locks where transactions acquire exclusive or shared locks on data items to control access. We have guaranteed isolation, however we may have deadlock problems.
We also have Timestamp-based Concurrency Control, where each transaction is associated with a timestamp. In addition to this, we have Snapshot isolation where each transaction sees a “snapshot” of the data at the beginning of the transaction, with the possibility of reading old data.
We will talk about these algorithms in more detail in another post.
Finally, we can list read and write access that have distinct implications on transaction operation and data management.
The goal is always to manage to ensure isolation and consistency.
In the case of conc readings streams, there are usually no problems, as a transaction reads the current data at the time of its reading.
However, concurrent writes can lead to problems such as dirty reading, where a transaction reads data modified by another transaction that has not yet committed.
In short…
You may notice that there are a lot of subtopics within each feature that make up a DBMS.
Despite dating back to the 1970s, relational DBMSs are very well applied to transactional systems where ACID support and data consistency are key.
After all this explanation about the DBMS and comparison with the archaic approach, I believe you got a better understanding of why we use relational DBMS.
For other posts about databases, visit www.simplificandoredes.com or our youtube channel https://www.youtube.com/@SimplificandoRedes
Until next time,
Juliana Mascarenhas

Juliana Mascarenhas
Data Scientist and Master in Computer Modeling by LNCC.
Computer Engineer
Tutorial: Using Port Forwarding in Packet Tracer
Tutorial: Web Server in Packet Tracer (Client-Server)

Email Server & Webmail Setup: Postfix, Dovecot, SnappyMail
Install Ubuntu Server 26 on VirtualBox (Step-by-Step)

How to Configure NAT in Packet Tracer (Step-by-Step)