Imagine that you have a series of PDF documents, or even another PDF file, to handle, merge and keep everything in just one file.
Let’s do this with REGEX and PyPDF2 with python
You, like me, have already been to sites that merge PDFs. But what if you can do it for free with Python? Or even create your own website to host this PDF “concatenator”?
That’s what we’re going to do now! In this project, we will concatenate PDF files based on the date contained in the file name.
Starting the Project – REGEX and PyPDF2 Libraries
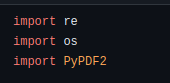
We will use the PyPDF2, re and os libs. With the exception of PyPDF2, both lib os and re are standard Python modules. Therefore, it is already installed.
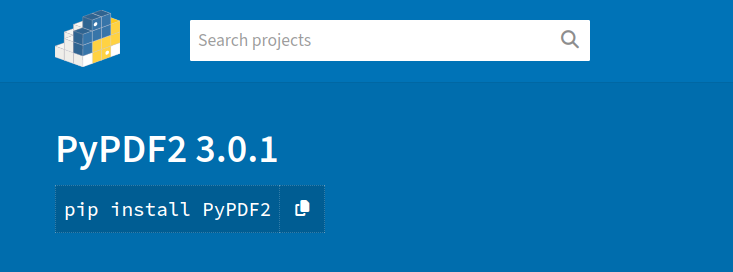
So, the only one to be installed in this case is PyPDF2. Perform the following installation in your virtual environment.
pip install PyPDF2 Within the code, you will import them like this:
Date extraction function with re – Regular Expression
Here we will use lib re’s search function to find occurrences of the pattern in the string.
The string in our case is the file name.
We define the pattern using raw string so that Python does not interpret special characters in our pattern.
pattern = r'\d{4}-\d{2}-\d{2}' Once the pattern is defined, we run the search and receive the result. Our returned result is composed of the Macth class from lib re.
With it we can use several methods that retrieve information from the search for the pattern, such as: position, string, beginning and end of the pattern.
If we have a result in hand, we will execute the group() method that returns the entire part of the string that matched the expression. Otherwise, we return None.
Take a look at how the function turned out:
def extract_date_from_filename(filename):
# Use regular expression to extract the date from the file name
pattern = r'\d{4}-\d{2}-\d{2}' # Expected date format YYYY-MM-DD
match = re.search(pattern, filename)
if match:
return match.group()
return NoneOrdering Files based on string pattern – Date
Now, let’s use the date extracted from the filenames to order our list of files.
The first piece of code uses a for to put all the files in a directory into a list.

This one-line for improves code readability and reduces the number of lines required.
In this case, we are checking the items within the directoy_path and adding the list only if the f is a file.
After creating our list (pdf_files_with_date) that will receive the tuples, let’s call the previous methods.
def sorting_files_by_date(directory_path):
files = [f for f in os.listdir(directory_path)
if os.path.isfile(os.path.join(directory_path, f))]
# var list of tuples
pdf_files_with_date = []
for file in files:
if file.lower().endswith('.pdf'):
date = extract_date_from_filename(file)
if date:
# tuple: (filename, default_date)
pdf_files_with_date.append((file, date))
return sorted(pdf_files_with_date, key=lambda x: x[1])We check if the files are pdf with the endswith() string method. If true, we call the function extract_data_from_file(file), passing the name of the current file as a parameter.
If there is a date (corresponding to the pattern) we add the tuple (file_name, found_date) to the list.
After scanning, the sorted function will sort the list by key.
Confused by lambda in history? So, let’s understand better.

Key receives the lambda function that allows checking the second element of the tuple.
In this case, x is an element of the list. Since the list is made up of tuples, we will be able to access its items through indices 0 and 1.
So, x[0] would be the first item, the file name. Now x[1] consists of the second element, the date associated with the file.
Ordering by date we will be able to merge the files in this directory in the correct way.
Notice that the list is relocated every time we call the function to a new subdirectory. This way, there will be no overlapping lists.
PDF concatenation function
Let’s then merge the files we received to carry out the freelance work.
In this case, we need to create a new structure equal to the original so that the pdf files are correctly associated with each directory.
But before that let’s order our files in each subdirectory.
You will notice that the pdf_files_sorted_by_date var is receiving precisely these already sorted files.
The next step is to allocate the PdfMerger() class. So we can add the files to be written into a single destination file.
pdf_files_sorted_by_date = sorting_files_by_date(directory_path)
merger = PyPDF2.PdfMerger()Then, each pdf file from our list will be added to the merger. Remember to add the full path.
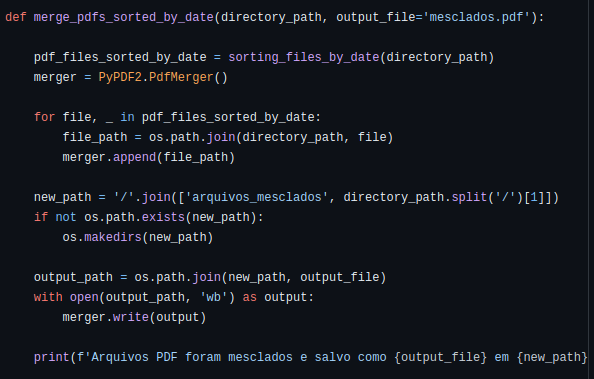
def merge_pdfs_sorted_by_date(directory_path, output_file='mesclados.pdf'):
pdf_files_sorted_by_date = sorting_files_by_date(directory_path)
merger = PyPDF2.PdfMerger()
for file, _ in pdf_files_sorted_by_date:
file_path = os.path.join(directory_path, file)
merger.append(file_path)
new_path = '/'.join(['archives_merged', directory_path.split('/')[1]])
if not os.path.exists(new_path):
os.makedirs(new_path)
output_path = os.path.join(new_path, output_file)
with open(output_path, 'wb') as output:
merger.write(output)
print(f'PDF files were merged and saved as {output_file} in {new_path}')If you don’t need to maintain the same structure as the original, after the merge you would simply write merger.write().
But in my case, the client wanted it that way. So….
#we define the new path and create it if it doesn't exist
new_path = '/'.join(['archives_merged', directory_path.split('/')[1]])
if not os.path.exists(new_path):
os.makedirs(new_path)We define the name of our destination file (single pdf).
output_path = os.path.join(new_path, output_file)Then, we write the single file using the write() method of the PdfMerger() class. Remember to open the target file as binary write (wb).
The finished function looks like the following image.
Main program
Ok, after creating all our functions we will test our code.
The name of the directory is associated with the structure I have in my Pycharm project. Take a look at the next image and you’ll understand better.
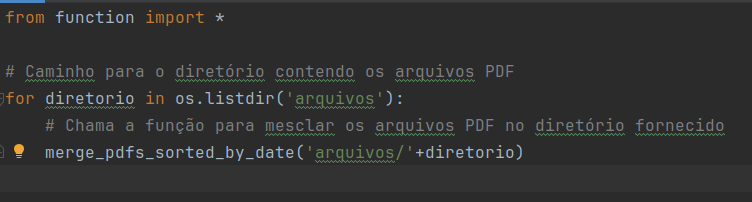
from function import *
# Path to the directory containing the PDF files
for directory in os.listdir('arquivos'):
# Call the function to merge the PDF files in the given directory
merge_pdfs_sorted_by_date('files/'+directory)
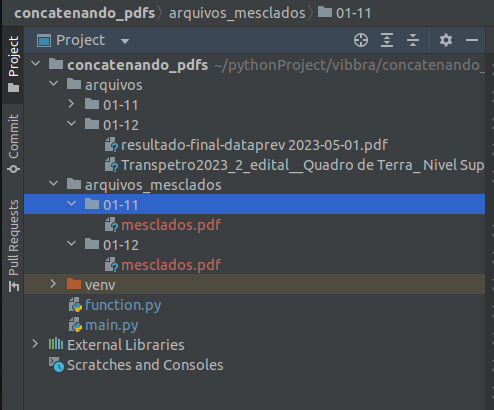
After executing the code my structure looked like this:
For more Python projects
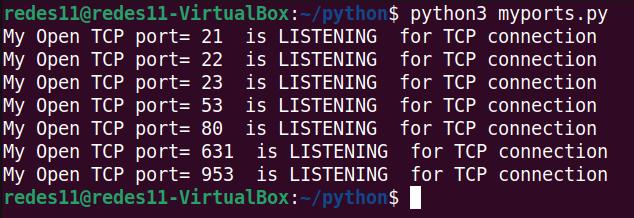
How to connect mysql using python
Python: show my TCP and UDP ports
Top Python Libraries for Data Science
Project playlist (under construction)
For those who prefer videos, follow our mini project playlist.

Email Server & Webmail Setup: Postfix, Dovecot, SnappyMail
Install Ubuntu Server 26 on VirtualBox (Step-by-Step)

How to Configure NAT in Packet Tracer (Step-by-Step)

Zabbix FIM: How to Setup File Integrity Monitoring
Configure DHCP in Packet Tracer: Server & Router Guide