
Imagine que você tem uma série de documentos em pdf, ou mesmo outro arquivo pdf, para mesclar e manter tudo em apenas um arquivo.
Vamos fazer isso com REGEX e PyPDF2 com python
Você, assim como eu, já foi em sites que mesclam PDF. Mas e se você puder fazer isso de graça com Python? Ou ainda criar seu próprio site para hospedar esse “concatenador” de pdf?
É isso que vamos fazer agora! Nesse projeto, vamos concatenar arquivos PDF com base na data contida no nome do arquivo.
Startando o Projeto – Bibiotecas REGEX e PyPDF2
Vamos usar as libs PyPDF2, re e os. Com exceção da PyPDF2, tanto a lib os como a re são módulos padrão do Python. Sendo assim, já vem instalada.
Então, a unica a ser instalada neste caso é a PyPDF2. Execute a seguinte instalação em seu ambiente virtual.
pip install PyPDF2 Dentro do código, você vai importa-las dessa forma:
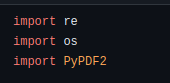
Função de extração da data com re – Regular Expression
Aqui vamos usar a função search da lib re para encontrar as ocorrências do padrão na string.
A string em nosso caso, é o nome do arquivo.
Definimos o padrão usando raw string para que o Python não interprete caracteres especiais em nosso padrão.
pattern = r'\d{4}-\d{2}-\d{2}' Uma vez definido o padrão, executados a busca e recebemos o resultado. O nosso resultado retornado é composto pela classe Macth da lib re.
Com ela podemos usar diversos métodos que recuperam as infos da busca pelo padrão, tais como: posição, string, início e fim do padrão.
Caso tenhamos um resultado em mãos, iremos executar o método group() que retorna a parte inteira da string que casou com a expressão. Caso contrário, retornamos None.
Da uma olhada em como ficou a função:
def extract_date_from_filename(filename):
# Utiliza expressão regular para extrair a data do nome do arquivo
pattern = r'\d{4}-\d{2}-\d{2}' # Formato de data esperado YYYY-MM-DD
match = re.search(pattern, filename)
if match:
return match.group()
return NoneOrdenando Arquivos baseado em padrão de string – Data
Agora, vamos usar a data extraida do nomes do arquivos para ordernar nossa lista de arquivos.
O primeiro pedaço de código usa um for para colocar dentro de uma lista todos os arquivos de um diretório.

Esse for em uma linha melhora a legibilidade do código e diminui o número de linhas necessárias.
Neste caso, estamos verificando os items dentro do directoy_path e adicionando a lista apenas se o f for um arquivo.
Após a criação da nossa lista (pdf_files_with_date) que receberá as tuplas, vamos chamar os métodos anteriores.
def sorting_files_by_date(directory_path):
files = [f for f in os.listdir(directory_path)
if os.path.isfile(os.path.join(directory_path, f))]
# var lista de tuplas
pdf_files_with_date = []
for file in files:
if file.lower().endswith('.pdf'):
date = extract_date_from_filename(file)
if date:
# tupla: (filename, data_padrao)
pdf_files_with_date.append((file, date))
return sorted(pdf_files_with_date, key=lambda x: x[1])Verificamos se os arquivos são pdf com o método de string endswith(). Caso verdadeiro chamamos a função extract_data_from_file(file), passando o nome do arquivo atual como parâmetro.
Caso haja uma data (correspondente ao padrão) adicionamos a tupla (nome_do_arquivo, data_encontrada) a lista.
Após a varredura a função sorted irá ordernar a lista a parte de uma key (chave).
Ficou confuso com o lambda na história? Então, vamos entender melhor.

Key recebe a função lambda que permite verificar o segundo elemento da tupla.
Neste caso, x é um elemento da lista. Já que a lista é formada por tuplas, seremos capazes de acessar seus items pelos indices 0 e 1.
Sendo assim, x[0] seria o primeiro item, o nome do arquivo. Já x[1] consiste no segundo elemento, a data associada ao arquivo.
Ordenando pela data seremos capazes de mesclar os arquivos desse diretório da maneira correta.
Perceba que a lista realocada toda vez que chamamos a função para um novo subdiretório. Assim, não teremos sobreposição de listas.
Função de concatenação dos PDFs
Vamos então mesclar os arquivos que recebemos para realizar o trabalho de freela.
Neste caso, precisamos criar uma nova estrutura igual a original para que os arquivos pdf estão corretamente associados a cada diretório.
Mas, antes disso vamos ordernar nossos arquivos de cada subdiretório.
Você vai perceber que a var pdf_files_sorted_by_date está recebendo justamente esses arquivos já ordernados.
O próximo passo está em alocar a classe PdfMerger(). Para que possamos adicionar os arquivos a serem escritos em um único arquivo destino.
pdf_files_sorted_by_date = sorting_files_by_date(directory_path)
merger = PyPDF2.PdfMerger()Então, cada arquivo pdf da nossa lista será adicionado ao merger. Lembre-se de adicionar o caminho completo.
def merge_pdfs_sorted_by_date(directory_path, output_file='mesclados.pdf'):
pdf_files_sorted_by_date = sorting_files_by_date(directory_path)
merger = PyPDF2.PdfMerger()
for file, _ in pdf_files_sorted_by_date:
file_path = os.path.join(directory_path, file)
merger.append(file_path)
new_path = '/'.join(['arquivos_mesclados', directory_path.split('/')[1]])
if not os.path.exists(new_path):
os.makedirs(new_path)
output_path = os.path.join(new_path, output_file)
with open(output_path, 'wb') as output:
merger.write(output)
print(f'Arquivos PDF foram mesclados e salvo como {output_file} em {new_path}')Se você não precisa manter a mesma estrutura da original, após o merge bastaria escrever o merger.write().
Mas no meu caso, o cliente queria dessa forma. Então….
#definimos o novo caminho e criamos caso não exista
new_path = '/'.join(['arquivos_mesclados', directory_path.split('/')[1]])
if not os.path.exists(new_path):
os.makedirs(new_path)Definimos o nome do nosso arquivo destino (único pdf).
output_path = os.path.join(new_path, output_file)Depois, escrevemos o arquivo unico usando o método write() da classe PdfMerger(). Lembre-se de abrir o arquivo destino como escrita binária (wb).
A função finalizada fica como na imagem a seguir.
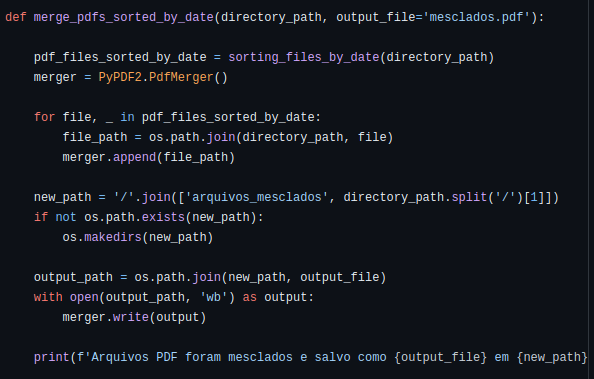
Programa principal
Ok, após criarmos todas as nossas funções iremos testar nosso código.
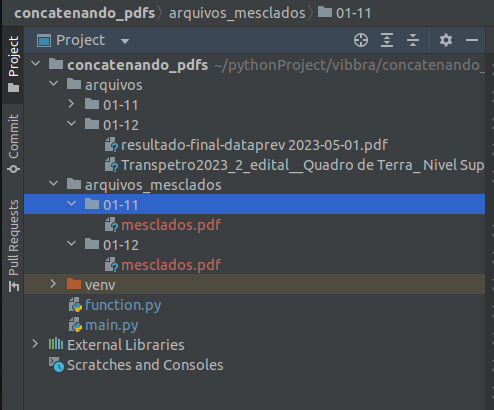
O nome do diretório esta associado a estrutura que tenho no meu projeto com Pycharm. De uma olhada na próxima imagem que você vai entender melhor.
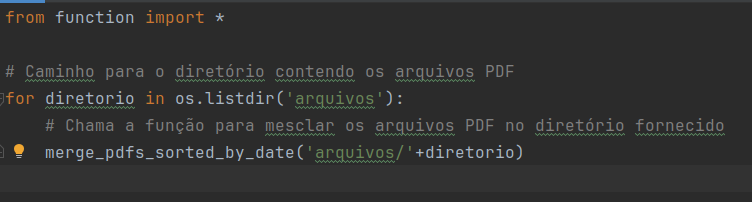
from function import *
# Caminho para o diretório contendo os arquivos PDF
for diretorio in os.listdir('arquivos'):
# Chama a função para mesclar os arquivos PDF no diretório fornecido
merge_pdfs_sorted_by_date('arquivos/'+diretorio)
Após a execução do código a minha estrutura ficou assim:
Para mais projetos com Python
Artigos e tutoriais SR: Projetos com Python em nosso site
Conectando ao MySQL com Python
Projeto para Portifólio: Sua primeira API com Python e MySQL
Principais Bibliotecas Python para Data Science: Manipulação e Visualização
Python: minhas portas TCP e UDP abertas
Playlist do projeto (em construção)
Para quem prefere vídeos, segue nossa playlista do mini projeto.

Juliana Mascarenhas
Data Scientist and Master in Computer Modeling by LNCC.
Computer Engineer

Packet tracer rede com 1 roteador
Nesse tutorial, vamos mostrar como configurar uma rede com apenas um roteador no Packettracer. Será…

Como Usar o Snap em Redes com Proxy (Linux)
Neste post, você vai aprender a configurar o Snap para funcionar atrás de um proxy,…

Como Criar uma Rede com Switch no Packet Tracer: Passo a Passo para Iniciantes
Neste tutorial prático, vou te mostrar como criar uma rede simples com switch utilizando o…

Por que usar o Kali Linux dentro do VirtualBox?
Neste artigo, veremos os principais motivos para considerar o uso do Kali Linux em um…

Como instalar pfblocker no pfsense: guia passo a passo
Hoje vamos aprender a instalar o pfBlockerNG no pfsense. O pfBlocker NG é uma excelente…
Crie sua Primeira Rede no Packet Tracer: Guia Passo a Passo para Iniciantes (2 Computadores)
Está pronto para dar o primeiro passo no mundo fascinante das redes de computadores? Neste…