
Este artigo apresenta a teoria relacionada aos métodos HTTP. Os principais, GET e POST, já foram falados no artigo sobre o protocolo HTTP (clique aqui para ser redirecionad ao artigo), contudo, também serão abordados aqui.
Métodos GET e POST
O método GET portanto, solicita ao servidor o envio dos objetos web de um determinado recurso, como por exemplo uma página. Os objetos web são os elementos que compõem uma página, como: texto, imagem, vídeo e inclusive a página em si.
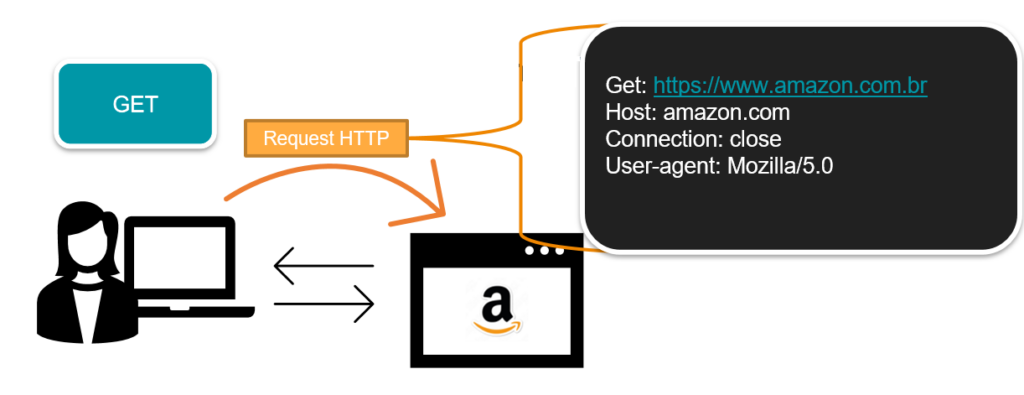
Outro método bastante comum, não tanto quando o GET, é o método POST. Neste caso, o cliente está submetendo uma informação ao servidor.
O servidor por sua vez recebe e trata esta informação que é enviada encapsulada no campo entity body da mensagem. Um exemplo intuitivo do método POST seria o preenchimento de um formulário, ou de um cadastro em um site de compras.
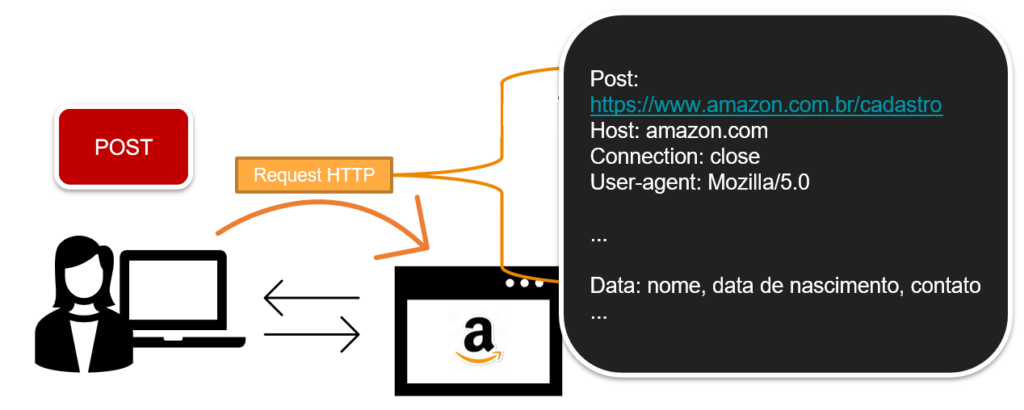
Repare que como o servidor é obrigado a tratar a informação de post, muitos sites colocam limitações a este método. Um usuário malicioso poderia utilizar este campo para enviar um Trojan, ou um código malicioso a ser executado no servidor.
Por isso, caso você tente realizar uma requisição do tipo POST por um agente que não seja um navegador, por exemplo: uma API JAVA, essa requisição retornará um erro de não permissão.
Outros métodos HTTP
Além dos métodos GET e POST, existe uma variedade de opções de manipulação de recursos, como: head, put, delete, trace entre outros. Abordaremos alguns destes métodos com breve explicação.
Caso o leitor deseje se aprofundar neste tema, referências serão citadas ao longo do texto.
O método HEAD solicita informações de metadados de um determinado recurso. Este método é útil para economizar largura de banda, ao verificar apenas se houve alguma modificação no recurso deste o ultimo download.
Caso o estado seja diferente do armazenado pelo cliente se faz necessária uma nova requisição – request.
O método PUT determina que as informações enviadas via entity body sejam armazenadas pelo recurso. Então, qual a diferença entre o PUT e o POST? No caso do método POST, a informação é apenas parte do processo.
Este é um método de uso mais geral, podendo ser aplicado em diferentes situações como: a identificação de um recurso e especificação de comandos para manipular uma entidade anexa, ou seja, os dados podem conter informações ou operações a serem executadas.
Ainda falando dos métodos, podemos citar o DELETE que obviamente apaga um determinado recurso.
O método TRACE consiste em uma chamada loop-back de um determinado recurso. Esse método permite ao cliente “ver” todo o processo de ida e volta da requisição.
Muito utilizado em procedimento de testes e diagnósticos relacionado a comunicação com o servidor.
Já o método OPTION descreve ao cliente as opções de configuração relacionadas à um determinado recurso do servidor. Com o CONNECT é possível determinar um tunelamento entre o cliente e o recurso alvo usando SSL.
O nosso último método descrito é o PATCH. Este foi definido posteriormente ao protocolo HTTP 1.0 na RFC 5789.
Quando existe a necessidade de uma modificação pontual de um determinado recurso, é a este método que recorremos. Se você quiser se aprofundar ainda mais nos métodos HTTP, segue o link.
Métodos HTTP Seguros
Cada método tem uma especialidade, ou seja, alguma operação executada a partir de seu acionamento. Alguns destes métodos apenas solicitam dados de um recurso do servidor. Estes são denominados métodos seguros.
Um método seguro é aquele que não acarreta em alteração do recurso e, portanto, não apresenta risco ao servidor.
São métodos seguros: GET, HEAD e OPTION. Visto que ações são executadas a partir do cliente, é intuitivo dizer que deve ser considerada com cautela as ações que um cliente possa infligir ao servidor.
As ações representam a interação entre cliente/servidor, que podem ser legitimas ou maliciosas. Tendo isso em mente, uma ação não segura pode acarretar em dano à algum recurso do servidor.
Por esse motivo é possível que um servidor não aceite requisições oriundas de um agende diferente do navegador.
Podemos ver esse exemplo acontecendo quando realizamos uma requisição POST através de uma API JAVA. Neste caso, será retornado um status de método não permitido.
Contudo, se a requisição é bem sucedida se realizada por intermédio do browser contendo o formulário. Não é garantido que um método GET não produza efeitos colaterais no servidor.
Contudo, não será de responsabilidade do cliente caso ocorra algum efeito colateral por método seguro.
Métodos idempotentes
Todo método seguro é idempotente, mas um método idempotente não necessariamente é um método seguro.
Ser um método idempotente significa que o resultado originado por sucessivas ações de requisição HTTP sempre terá o mesmo efeito que uma única requisição. Outros exemplos de métodos idempotentes não seguros, são: PUT e DELETE.
Referências Bibliográficas
- HTTP Methods por Mozilla developer
- Métodos seguros por MDN
- RFC 2616 – Definição e métodos
- Kurose, James F., and Keith W. Ross. “Redes de Computadores e a Internet.” Pearson – 6° edição
- Tanenbaum, Andrew et al. “Redes de Computadores.” Editora Pearson – 5° edição.

Juliana Mascarenhas
Data Scientist and Master in Computer Modeling by LNCC.
Computer Engineer

Controle de Congestionamento em Redes: Otimizando Eficiência e Alocação de Banda
Este post técnico aborda os mecanismos de controle de congestionamento, com foco na camada de…

AIDE : IDS para Linux Ubuntu Instalação e Configuração
Apresentamos um tutorial de instalação e configuração do IDS AIDE no Linux Ubuntu. O AIDE…

Packet tracer rede com 1 roteador
Nesse tutorial, vamos mostrar como configurar uma rede com apenas um roteador no Packettracer. Será…

Como Usar o Snap em Redes com Proxy (Linux)
Neste post, você vai aprender a configurar o Snap para funcionar atrás de um proxy,…

Como Criar uma Rede com Switch no Packet Tracer: Passo a Passo para Iniciantes
Neste tutorial prático, vou te mostrar como criar uma rede simples com switch utilizando o…

Por que usar o Kali Linux dentro do VirtualBox?
Neste artigo, veremos os principais motivos para considerar o uso do Kali Linux em um…