
Quais são as principais características, ou melhor, propriedades de um SGBD? Quando optar por um banco de dados? Existe um cenário em que ele não é utilizado? Este artigo trata justamente deste assunto.

Caso você queira entender um melhor do realmente se trata banco de dados acesse o primeiro artigo do tema: Entenda o que são Banco de Dados
Você pode estar se perguntando… “Mas as formas de armazenamento e processamento de dados tradicionais (arquivos, por ex.) resolvem o problema. Por que utilizar um SGBD?
Vamos entender as diferenças na abordagem de mecanismos antigos (ex. files) de processamento de dados com a abordagem de SGBD.
Livros SQL + Dados



Relembrando Abordagem tradicional
Relembrando o que foi falado no artigo Entenda o que são Banco de Dados, em uma abordagem tradicional, o desenvolvedor define os requisitos gerenciamento dos dados tanto do programa quanto do tipo de armazenamento a ser utilizado.
Assim, os arquivos fazem parte da implementação do programa. Parece tudo certo, mas alguns pontos são problemáticos. Um exemplo disso está no controle de concorrência de acesso e redundância.
Dessa forma, haverá repetição de dados, ou seja armazenamento de dados redundantes desnecessariamente. Podemos perceber então, o problema de desperdício de espaço de armazenamento e retrabalho.
Características de um SGBD
Um SGBD é baseado na abordagem de utilização de um repositório único que mantém os dados. Claramente, não estamos considerando um ambiente distribuído. Esse é assunto para outro post….
Esses dados por sua vez são acessados por diferentes aplicações, ou recuperados através de queries e transações. O SGBD é responsável por armazenar, gerenciar, controle e manter o estado consistente dos dados.
Podemos descrever um SGBD pelas suas as principais características, descrevendo então a abordagem de BDs. São elas:
- Auto-descrição
- Isolamento entre dados e programa
- Abstração de dados
- Suporte a múltiplas visões dos dados persistidos
- Compartilhamento de dados
- Processamento de transações multiusuário
Natureza auto-descritiva SGBD
Essa característica advém do fato do SGBD conter além do banco de dados as informações de metadados e descrição do esquema do banco de dados.
Em outras palavras, o SGBD possui uma descrição completa da estrutura e restrições do banco de dados.
Essa estrutura é denominada catálogo. Nela estão contidas as estruturas dos arquivos, o tipo e formato de, ou seja, os metadados. Este módulo do SGBD também é conhecido como catálogo de metadados.
P.S. sistemas baseados em NoSQL não utilizam metadados, visto que cada estrutura dos dados é auto-descritiva contendo o nome e valor dos itens.
O catálogo é utilizado tanto pelo SGBD quanto pelos usuários que precisam de informações sobre o banco de dados.
Quando você executa DESC <table> no MySQL você recupera os metadados da tabela em questão.
O SGBD deve trabalhar normalmente independentemente do tipo de aplicação que utilize os dados: dados de universidade, bd de bancos, ou de empresas, desde que a definição do bd esteja definida no catálogo.
Consegue perceber que na abordagem “tradicional” (ou arcaica) cada aplicação precisava se preocupar com o contexto dos dados? Pois é, mais um ponto para o SGBD.
Sendo assim, a aplicação tipicamente iria acessar e gerenciar a estrutura dos dados que neste caso, faz parte do programa de aplicação.
No cenário onde o SGBD é dedicado aos dados, o programa acessa os dados de maneira “transparente” enviando apenas poucas informações sobre os dados a serem recuperados.
Como ex: SELECT CONCAT(name,’ ’, lastname), email, phone FROM CUSTOMERS WHERE YEAR(data_login) == YEAR(current_date())
O SGBD, por sua vez, é capaz de acessar diversos tipos de bancos de dados extraindo e utilizando as informações do catálogo de metadados.
Isolamento Programa e Dados – SGBD
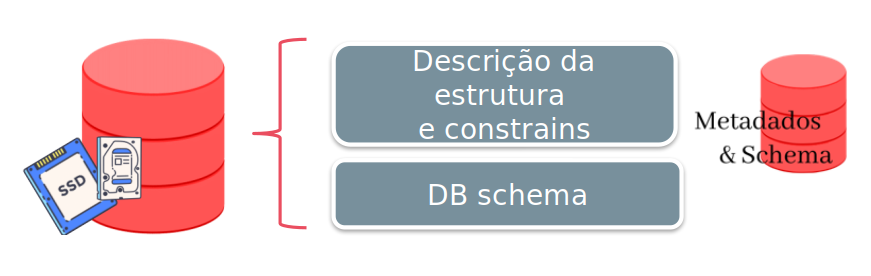
Na abordagem “arcaica”, a estrutura dos dados está embutida, ou “embedada”, na aplicação. Isso cria uma série de complicações de criação e manutenção de código.
Qualquer alteração na estrutura dos arquivos impactará diretamente a aplicação.
Contudo, no SGBD há uma separação clara entre a estrutura do BD e os dados propriamente ditos. Esse processo é denominado independência de programa/dados.
Exemplo de isolamento/abstração
Vamos entender melhor ….
Suponha um programa escrito para acessar uma base de dados de estudantes. Neste programa consta a estrutura dos dados.
Agora, imagine que haja a necessidade de modificação deste estrutura e adicionar o campo data de nascimento. Todo o programa será reestruturado para atender a esta modificação. Caso contrário, acarretará em falha.
Por outro lado, um SGBD possui a característica de isolamento que deverá refletir essa mudança apenas no catálogo do BD.
Dessa forma, quando o SGBD procurar por este atributo no acesso ao catálogo, a nova estrutura será acessada.
OBS: Apesar desse isolamento, mudanças bruscas no esquema do banco de dados não são triviais e vem acrescido de downtimes e outras questões.
Quando falamos de modelagem, precisamos estar atentos a melhor maneira possível de representar esses dados.
Abstração
Continuando … A característica que permite essa independência entre dados e programa é a Abstração. O programa abstraiu a estrutura, delegando ao SGBD essa tarefa.
“Então, Juliana? Como a aplicação solicita os dados?” Com conhecimento prévio das tabelas e atributos que compõem o BD a fim de criar queries SQL.
Temos então, uma representação conceitual dos dados sem a necessidade de apresentação a detalhes de implementação como: armazenamento e operações. Temos o que é chamado de modelo de dados.
Informalmente o modelo de dados é a abstração dos dados propriamente ditos utilizados na representação do mini-mundo. Este modelo é composto pelos conceitos lógicos, tais como: objetos, propriedades e inter-relacionamentos.
As operações contidas na aplicação irão utilzia o modelo de dados como base para realizar suas queries e recuperar, adicionar, remover ou atualizar dados no SGBD.
Table Views – Visões
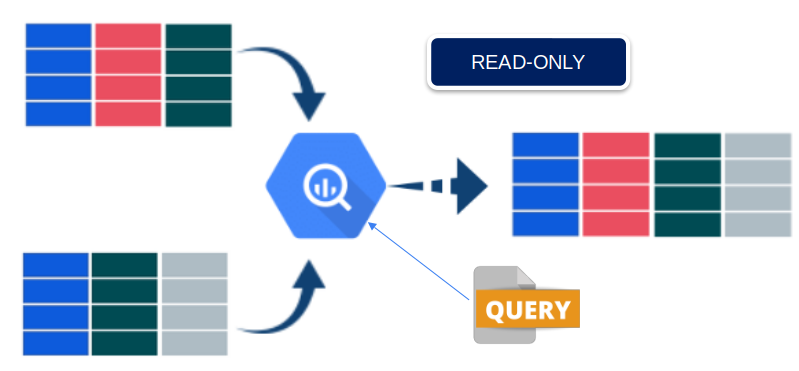
Um dos grandes recursos de SGBD, são as “views” desempenham um papel fundamental ao aprimorar a interação entre usuário e os dados armazenados.
As views, também conhecidas como visões, oferecem uma representação virtual dos dados contidos nas tabelas associadas. Isso permite aos usuários realizar consultas complexas e análises sem a necessidade de acessar diretamente as tabelas originais.
Isso acontece de maneira transparente já que o DBA, ou analista de banco de dados, cria as visões com base nos questionamentos mais frequentes.
Uma das principais vantagens das views é a redução do consumo de banda e recursos do sistema. Em consultas que envolvem múltiplas tabelas e operações complexas, as views atuam como camadas intermediárias.
Elas armazenam os resultados das consultas e consultas frequentemente utilizadas, minimizando a necessidade de repetir cálculos e reduzindo a sobrecarga do sistema.
Além disso, existem outros pontos de vantagem de sua utilização. Estes eu vou deixar para um post dedicado ao assunto.
Contudo, nem tudo são flores. Há momentos em que as views podem atrapalhar. Um exemplo está no acesso de dados em tempo real, visto que as vies são originadas por um pré-processamento dos dados.
COMPARTILHAMENTO E MULTIUSUÁRIOS
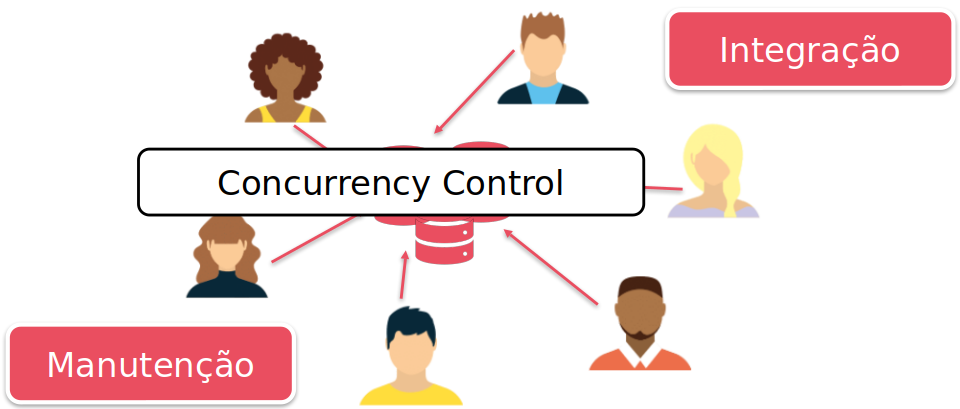
É comum em ambientes de banco de dados várias transações concorrentes, sendo executadas. Esse é um dos motivos de sua utilização.
Sendo assim, questões como consistência, isolamento e atomicidade precisam ser cuidadosamente gerenciadas. Para isso, diversos algoritmos e técnicas são empregados.
Quando falamos de banco de dados relacional é certo associarmos o acrônimo ACID a ele. Sistemas transacionais precisam ter suporte ao modelo ACID. Mas o que significa ACID?
- A – Atomicidade
- C – Controle
- I – Isolamento
- D – Durabilidade
Para entender melhor esse cenário vamos entender cada parte do acrônimo. A atomicidade está associada à característica dos dados persistidos no banco.
Os dados devem ser atômicos, em outras palavras imutáveis. Os dados a serem inseridos no sistema devem obedecer as regras relacionadas ao atributo (campo).
Esses dados são inseridos através das transações. Essas transações são 8 ou 80, ou seja, ela ocorre sem erros ou volta ao estado anterior consistente. Commit ou abort
O controle está relacionado ao controle do SGBD em relação às transações. O controle está relacionado ao estado consistente do banco de dados. Controle = consistência dos dados
Isolamento mantém a operação independente das transações. Sendo assim, uma transação em execução não pode sofrer interferência de outra transação submetida ao SGBD.
Por fim… você deve ter percebido que as características possuem uma interdependência. Isso significa que cada aspecto do acrônimo ACID influencia positivamente no outro.
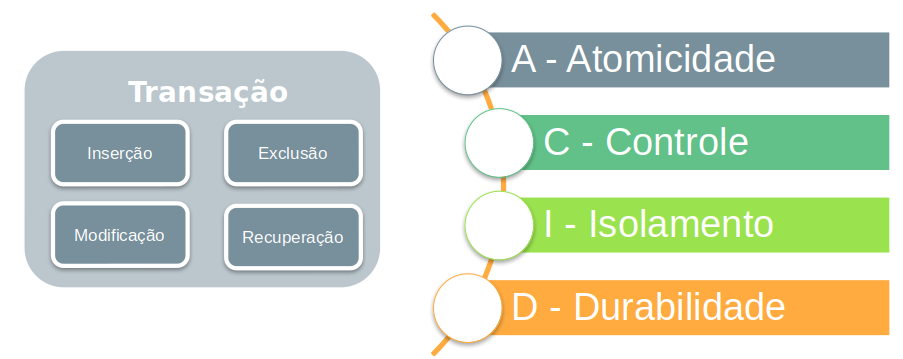
Nosso último elemento, D – Durabilidade, está relacionado a garantia de modificação bem sucedida dos dados durante a transação, mesmo em caso de falha do sistema.
O que são bloqueios?
Em casos de crash do server, por exemplo, o SGBD pode recuperar o estado anterior a falha pelos logs do sistema.
Dentre os principais algoritmos adotados para controle de concorrência por um SGBD, temos:
Bloqueios onde as transações adquirem bloqueios exclusivos ou compartilhados em itens de dados para controlar o acesso. Temos o isolamento garantido, contudo podemos ter problemas de deadlocks.
Temos ainda o controle de Concorrência Baseado em Carimbo (Timestamp-based Concurrency Control), onde cada transação é associada a um carimbo temporal. Além deste temos o isolamento de Snapshot onde cada transação enxerga um “snapshot” dos dados no início da transação, podendo haver leitura de dados antigos.
Falaremos destes algoritmos em mais detalhes em um outro post.
Por fim, podemos listar o acesso de leitura e escrita que possuem implicações distintas na operação das transações e no gerenciamento dos dados.
O objetivo é sempre gerenciar para garantir o isolamento e a consistência.
No caso de leituras concorrentes, normalmente não há problemas, pois uma transação lê os dados atuais no momento da sua leitura.
Contudo, escritas concorrentes podem acarretar em problemas como a leitura suja (dirty read), onde uma transação lê dados modificados por outra transação que ainda não foi confirmada.
Resumindo…
Você pode perceber que são muito subtópicos dentro de cada característica que compõem um SGBD.
Apesar de datar de 1970, SGBDs relacionais são muito bem aplicados a sistemas transacionais onde o suporte a ACID e a consistência dos dados é a chave do negócio.
Após toda essa explicação sobre o SGBD e comparação com a abordagem arcaica, acredito que você conseguiu entender melhor o por que usamos SGBDs relacionais.
Para outros posts sobre banco de dados acesse www.simplificandoredes.com ou nosso canal no youtube https://www.youtube.com/@SimplificandoRedes
Até a próxima,
Juliana Mascarenhas

Juliana Mascarenhas
Data Scientist and Master in Computer Modeling by LNCC.
Computer Engineer

Controle de Congestionamento em Redes: Otimizando Eficiência e Alocação de Banda
Este post técnico aborda os mecanismos de controle de congestionamento, com foco na camada de…

AIDE : IDS para Linux Ubuntu Instalação e Configuração
Apresentamos um tutorial de instalação e configuração do IDS AIDE no Linux Ubuntu. O AIDE…

Packet tracer rede com 1 roteador
Nesse tutorial, vamos mostrar como configurar uma rede com apenas um roteador no Packettracer. Será…

Como Usar o Snap em Redes com Proxy (Linux)
Neste post, você vai aprender a configurar o Snap para funcionar atrás de um proxy,…

Como Criar uma Rede com Switch no Packet Tracer: Passo a Passo para Iniciantes
Neste tutorial prático, vou te mostrar como criar uma rede simples com switch utilizando o…

Por que usar o Kali Linux dentro do VirtualBox?
Neste artigo, veremos os principais motivos para considerar o uso do Kali Linux em um…